Joseph L. Goldstein received the David Rockefeller Award for Extraordinary Service and honorary degrees were bestowed upon Carolyn Bertozzi and Francis S. Collins.
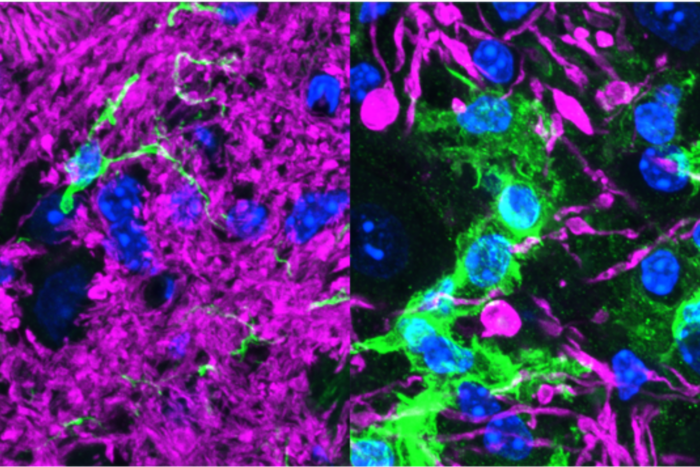
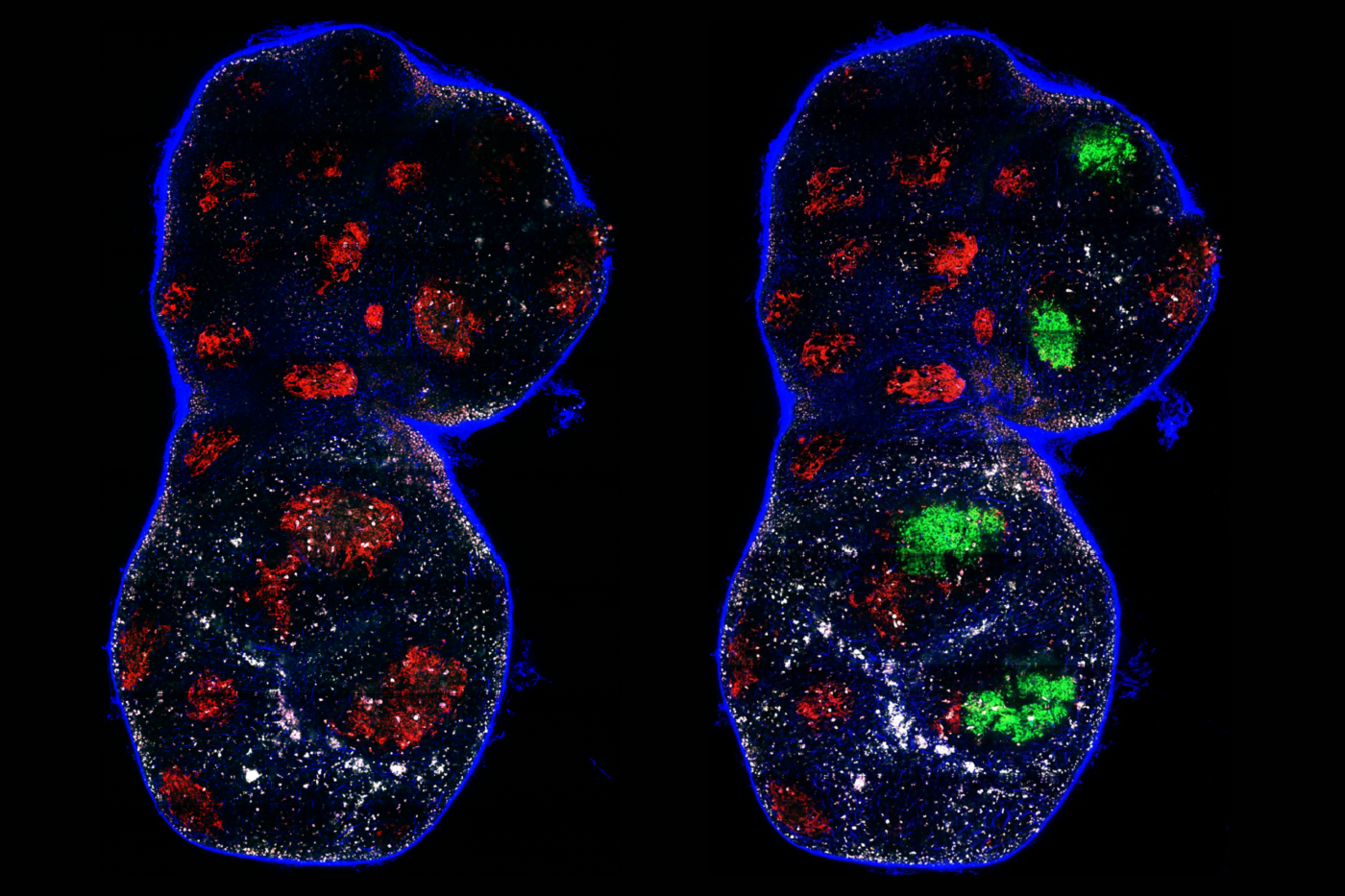
Gabriel D. Victora's team has turned germinal centers into a living laboratory for one of biology's oldest questions: how much of evolution is shaped by chance?
A new study reveals how germinal centers produce powerful antibodies through noisy rounds of mutation and selection, offering new insight into vaccine design—and larger themes in evolution.
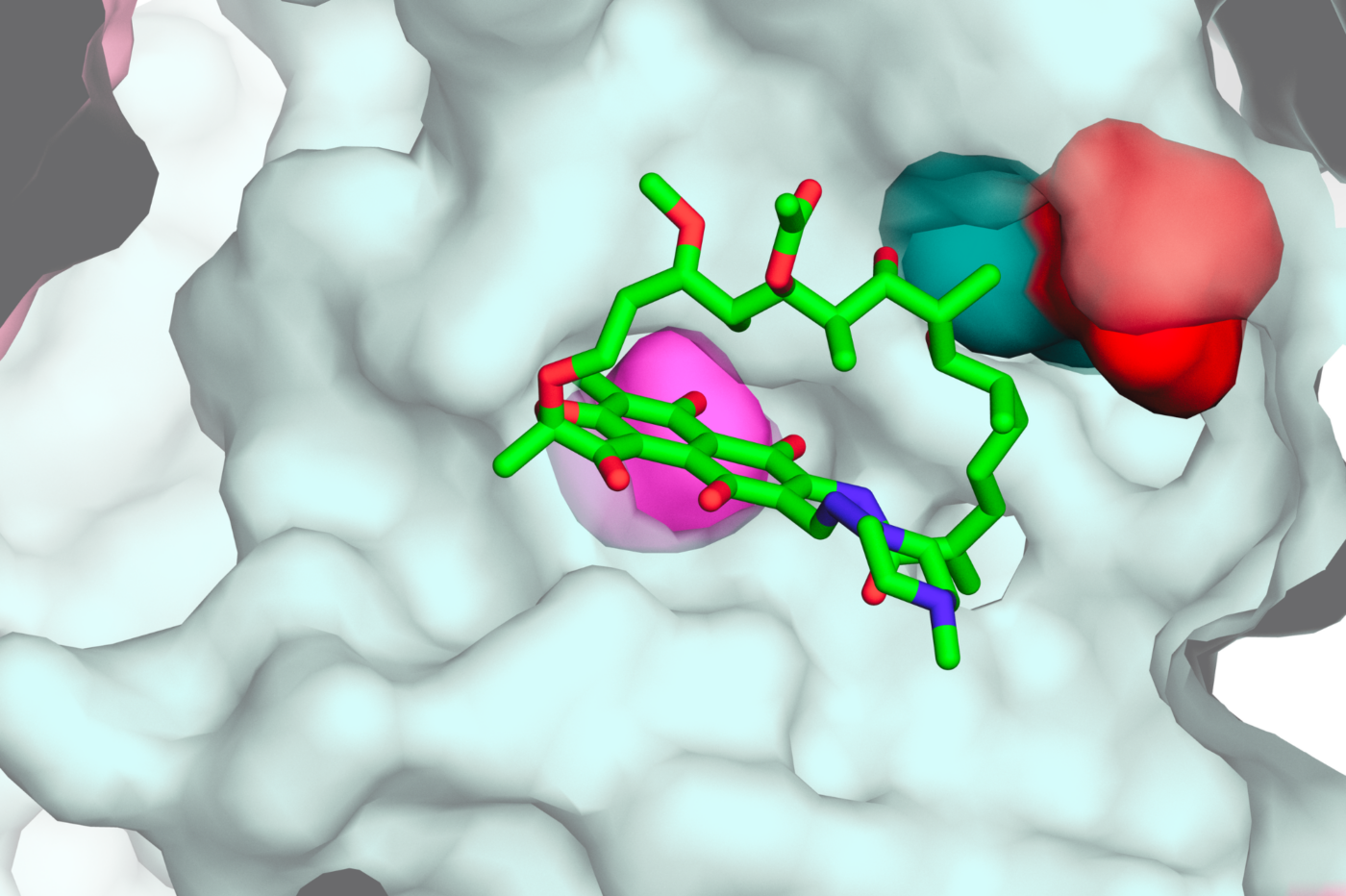
One of the most common drug resistance mutations in tuberculosis creates subtle metabolic weaknesses that could be exploited with future combination therapies.
President Lifton reflects on the university’s long history of innovation, why modern medicine would be unthinkable without basic science, and how the next wave of discoveries will shape the future.